Classe EventEmitter
const eventEmitter = new EventEmitter();const eventEmitter = new EventEmitter();

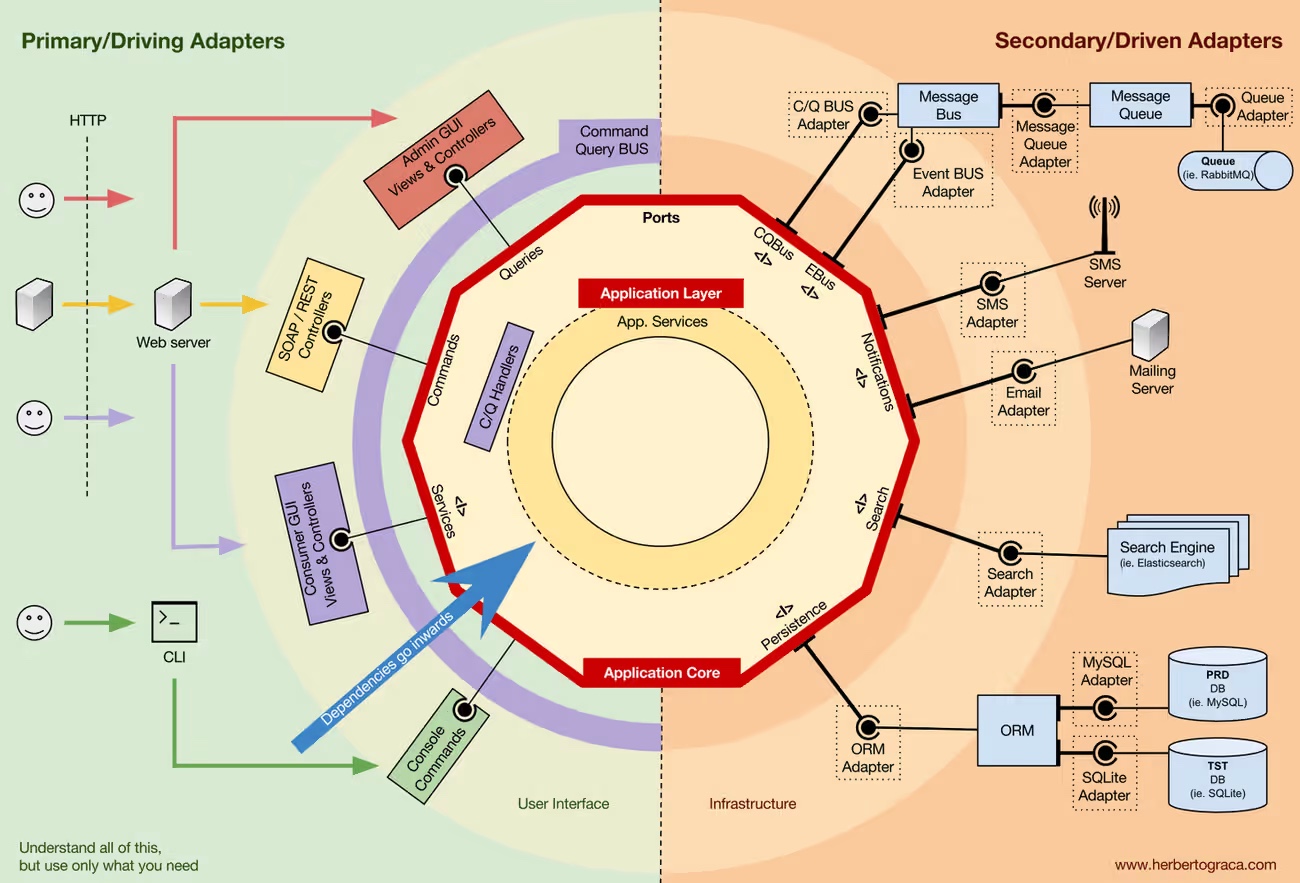
Architecture événementielle
Une grande partie de l’API principale de Node.js est construite autour d’une architecture événementielle asynchrone idiomatique dans laquelle certains types d’objets (appelés "émetteurs") émettent des événements nommés qui provoquent l’appel d’objets Function ("auditeurs").
Par exemple : un objet net.Server émet un événement chaque fois qu’un pair s’y connecte ; un fs.ReadStream émet un événement lorsque le fichier est ouvert ; un flux émet un événement chaque fois que des données sont disponibles pour être lues.
Aller plus loin dans les origines
EventEmitter utilise les cycles de boucle d’événements de base de LibUV pour délivrer des événements et exécuter des rappels, ce qui signifie que lorsque vous émettez un événement, il va être ajouté dans la pile de déclenchement d’événements de LibUV pour être déclenché lorsqu’il y a un temps de synchronisation disponible pour cette opération.
Event loop
Boucle d’événement ou d’E/S: la boucle d’événement ou d’E/S utilise une approche d’E/S asynchrone à un seul thread, elle est donc liée à un seul thread. Pour exécuter plusieurs boucles d’événements, chacune de ces boucles d’événements doit être exécutée sur un thread différent.
Libuv maintient une file d’attente d’événements et un démultiplexeur d’événements. La boucle écoute les E/S entrantes et émet un événement pour chaque requête. Les requêtes sont ensuite affectées à un gestionnaire spécifique (dépendant du système d’exploitation). Après une exécution réussie, le rappel enregistré est mis en file d’attente dans la file d’attente des événements qui sont exécutés en continu un par un.
Exemple: si une demande réseau est effectuée, un rappel est enregistré pour cette demande et la tâche est affectée au gestionnaire. Jusqu’à ce qu’il soit effectué, d’autres opérations se poursuivent. En cas d’exécution/d’arrêt réussi, le rappel enregistré est mis en file d’attente dans la file d’attente d’événements qui est ensuite exécutée par le thread principal après l’exécution des rappels précédents déjà présents dans la file d’attente.
EventEmitter
Tous les objets qui émettent des événements sont des instances de la classe EventEmitter. Ces objets exposent une fonction eventEmitter.on() qui permet d’attacher une ou plusieurs fonctions à des événements nommés émis par l’objet. Généralement, les noms d’événements sont des chaînes en casse camel, mais n’importe quelle clé de propriété JavaScript (ex: Symbol) valide peut être utilisée.
Lorsque l’objet EventEmitter émet un événement, toutes les fonctions attachées à cet événement spécifique sont appelées de manière synchrone. Toutes les valeurs renvoyées par les écouteurs appelés sont ignorées et rejetées.
import { EventEmitter } from 'node:events'; const myEmitter = new EventEmitter(); myEmitter.on('event', () => { console.log('an event occurred!'); }); myEmitter.emit('event');import { EventEmitter } from 'node:events'; const myEmitter = new EventEmitter(); myEmitter.on('event', () => { console.log('an event occurred!'); }); myEmitter.emit('event');
Passez des arguments
La méthode eventEmitter.emit() permet de transmettre un ensemble arbitraire d’arguments aux fonctions d’écoute. Gardez à l’esprit que lorsqu’une fonction d’écouteur ordinaire est appelée, la norme this mot-clé est intentionnellement définie pour référencer l’instance EventEmitter à laquelle l’écouteur est attaché.
import { EventEmitter } from 'node:events'; const myEmitter = new EventEmitter(); myEmitter.on('event', function(a, b) { console.log(a, b, this, this === myEmitter); }); myEmitter.emit('event', 'a', 'b');import { EventEmitter } from 'node:events'; const myEmitter = new EventEmitter(); myEmitter.on('event', function(a, b) { console.log(a, b, this, this === myEmitter); }); myEmitter.emit('event', 'a', 'b');
EventEmitter asynchrone
L’EventEmitter appelle tous les écouteurs de manière synchrone dans l’ordre dans lequel ils ont été enregistrés. Cela garantit le bon séquencement des événements et permet d’éviter les conditions de course et les erreurs logiques. Le cas échéant, les fonctions d’écoute peuvent basculer vers un mode de fonctionnement asynchrone à l’aide de setImmediate() ou process.nextTick()
import { EventEmitter } from 'node:events'; const myEmitter = new EventEmitter(); myEmitter.on('event', (a, b) => { setImmediate(() => { console.log('this happens asynchronously'); }); }); myEmitter.emit('event', 'a', 'b');import { EventEmitter } from 'node:events'; const myEmitter = new EventEmitter(); myEmitter.on('event', (a, b) => { setImmediate(() => { console.log('this happens asynchronously'); }); }); myEmitter.emit('event', 'a', 'b');
Issues EventEmitter
Les écouteurs.
Le problème d’avoir trop d’écouteurs. Par défaut, EventEmitter veut que nous maintenions le nombre d’écouteurs aussi bas que possible car sur chacun, il exécute une boucle de synchronisation sur les rappels, ce qui bloque toute la boucle d’événements.
La limite initiale est de seulement 25 abonnés par événement, ce qui est tout à fait acceptable pour une application moyenne, MAIS vous pouvez augmenter ce nombre autant que vous le souhaitez. Le principal inconvénient d’avoir de grands nombres est le coût des performances du processeur qui en découle.
Le problème du maintien du niveau de concurrence.
Lorsque vous faites tourner N fois une opération asynchrone, cela crée une file d’attente de promesses dans le pool de threads, cela signifie que si vous émettez un événement (qui est synchronisé), N fois la file d’attente se développe de la même manière. Pour Node.js, cela pourrait entraîner des plantages de dépassement de mémoire ou d’autres erreurs inattendues.
Conclusion
EventEmitter n’est pas pour chaque cas d’utilisation d’application, et vous pouvez certainement le remplacer par une implémentation personnalisée, MAIS le plus important est de garder à l’esprit qu’EventEmitter est lié aux événements de LibUV qui est le principal moteur de boucle d’événements pour Node .js.
Typescript EventEmitter
type Events = { ["myEvent"]: (event: string) => Promise<void>; }type Events = { ["myEvent"]: (event: string) => Promise<void>; }
Typage EventEmitter
Typage partielle de la classe EventEmitter
type ListenerSignature<L> = { [E in keyof L]: (...args: any[]) => any; } interface TypedPartialEventEmitter<Events extends ListenerSignature<Events>> { on: <E extends keyof Events>(event: E, listener: Events[E]) => this; emit: <E extends keyof Events>(event: E, ...args: Parameters<Events[E]>) => boolean; }type ListenerSignature<L> = { [E in keyof L]: (...args: any[]) => any; } interface TypedPartialEventEmitter<Events extends ListenerSignature<Events>> { on: <E extends keyof Events>(event: E, listener: Events[E]) => this; emit: <E extends keyof Events>(event: E, ...args: Parameters<Events[E]>) => boolean; }
Usage exemple
const Event = Symbol("Event"); type Events = { [Event]: (event: number) => Promise<void>; } const myEvents = new EventEmitter() as TypedPartialEventEmitter<Events>; // => type '"hello"' is not assignable to parameter of type 'number' myEvents.emit(Event, "hello");const Event = Symbol("Event"); type Events = { [Event]: (event: number) => Promise<void>; } const myEvents = new EventEmitter() as TypedPartialEventEmitter<Events>; // => type '"hello"' is not assignable to parameter of type 'number' myEvents.emit(Event, "hello");
Architecture 3 tiers
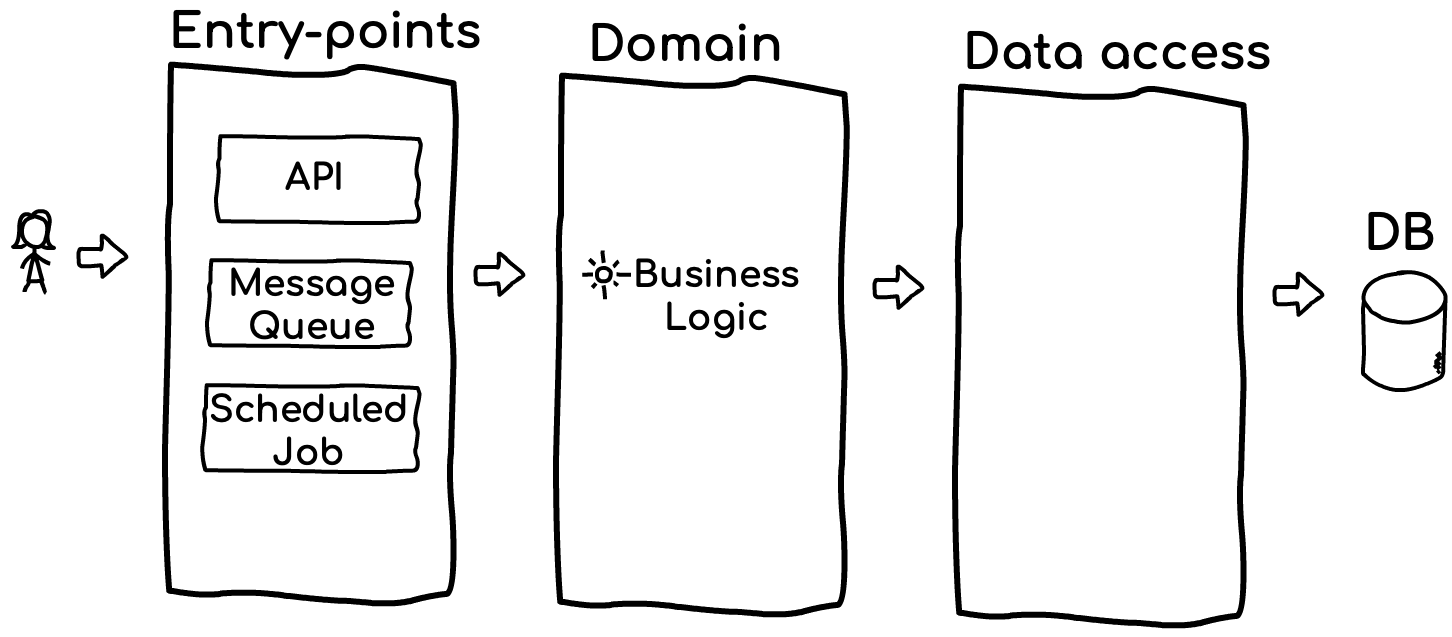
Entrypoints
C’est la porte de l’application où les flux commencent et les demandes arrivent. Notre exemple de composant a une API REST (c’est-à-dire des contrôleurs d’API), c’est un type de point d’entrée. Il peut y avoir d’autres points d’entrée comme une tâche planifiée, une CLI, une file d’attente de messages, etc. Quel que soit le point d’entrée avec lequel vous traitez, la responsabilité de cette couche est minime - recevoir les demandes, effectuer l’authentification, transmettre la demande au code interne et gérer les erreurs. Par exemple, un contrôleur reçoit une demande d’API, puis il ne fait rien de plus que d’authentifier l’utilisateur, d’extraire la charge utile et d’appeler une fonction de couche de domaine.
Domain
Un dossier contenant le cœur de l’application où les flux, la logique et la structure des données sont définis. Ses fonctions peuvent desservir n’importe quel type de points d’entrée - qu’il soit appelé depuis l’API ou la file d’attente de messages, la couche de domaine est indépendante de la source de l’appelant. Le code ici peut appeler d’autres services via HTTP/file d’attente. Il est également probable qu’il récupère et enregistre des informations dans une base de données, pour cela, il appellera la couche d’accès aux données.
Data-access
L’intégralité de la fonctionnalité et de la configuration de votre interaction avec la base de données est conservée dans ce dossier.
Organisez votre projet en composants
Le pire obstacle des énormes applications est la maintenance d’une base de code immense contenant des centaines de dépendances - un tel monolithe ralentit les développeurs tentant d’ajouter de nouvelles fonctionnalités. Pour éviter cela, répartissez votre code en composants, chacun dans son dossier avec son code dédié, et assurez vous que chaque unité soit courte et simple.
Autrement : Lorsque les développeurs qui codent de nouvelles fonctionnalités ont du mal à réaliser l’impact de leur changement et craignent de casser d’autres composants dépendants - les déploiements deviennent plus lents et plus risqués. Il est aussi considéré plus difficile d’élargir un modèle d’application quand les unités opérationnelles ne sont pas séparées.
Organisez vos composants en strates, gardez la couche web à l’intérieur de son périmètre
Chaque composant devrait contenir des « strates » - un objet dédié pour le web, un pour la logique et un pour le code d’accès aux données. Cela permet non seulement de séparer clairement les responsabilités mais permet aussi de simuler et de tester le système de manière plus simple. Bien qu’il s’agisse d’un modèle très courant, les développeurs d’API ont tendance à mélanger les strates en passant l’objet dédié au web (Par exemple Express req, res) à la logique opérationnelle et aux strates de données - cela rend l’application dépendante et accessible seulement par les frameworks web spécifiques.
Autrement : Les tests, les jobs CRON, les déclencheurs des files d’attente de messages et etc ne peuvent pas accéder à une application qui mélange les objets web avec les autres strates.
Externalisez les utilitaires communs en paquets NPM
Dans une grande appli rassemblant de nombreuses lignes de codes, les utilitaires opérant sur toutes les strates comme un logger, l’encryption et autres, devraient être inclus dans le code et exposés en tant que paquets NPM privés. Cela permet leur partage au sein de plusieurs projets.
Autrement : Vous devrez inventer votre propre roue de déploiement et de dépendance
Clean architecture
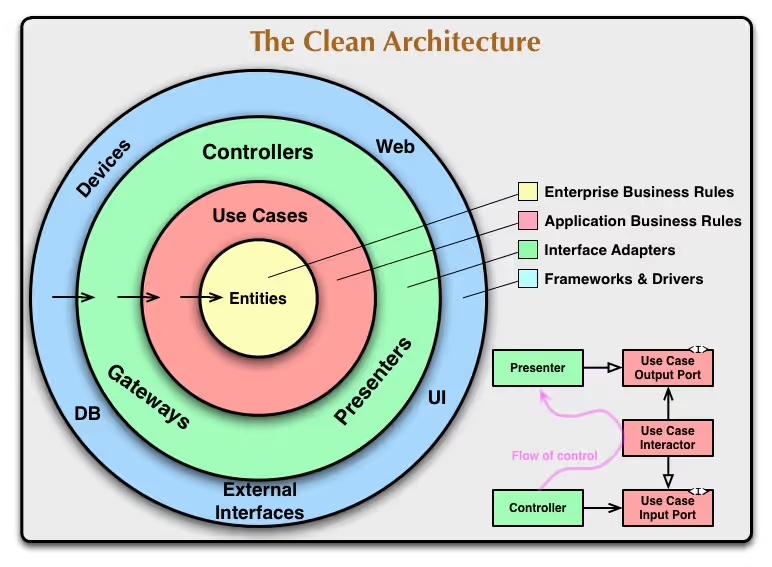
Adapters